
python基础知识
基础
标识符
除下划线同C,并且py3支持中文和非ASCII字符了
以单下划线开头的代表不能直接访问的类属性,要通过借口访问双下划线开头和结尾的是特殊方法专用标识
保留字
| and | exec | not |
|---|---|---|
| assert | finally | or |
| break | for | pass |
| class | from | |
| continue | global | raise |
| def | if | return |
| del | import | try |
| elif | in | while |
| else | is | with |
| except | lambda | yield |
多行
1 | '''可以写 |
不换行输出
1 | # 有限制 |
变量
==不用声明==
可以有a = b = c = 1(三个变量在一块内存!)以及a, b, c = 1, 2, 'hahaha'
标准数据类型
- Numbers
- String
- List
- Tuple 元组
- Dictionary 字典
- Set 集合
Numbers
- int
long (py3移除)- bool(是int的子类)
- float
- complex
a+bj || complex(a,b)
1 | a = 1 |
String
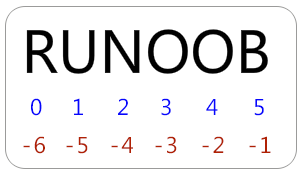
1 | s = "hello" |
List
1 | print([1,2,'dfasf']) |
Tuple
只读列表
1 | tuple = ( 2, 2, 2.2 ) |
Set
1 | parame = { val1, val2, val3 } |
Dictionary
1 | dic = {} |
字符串
Python字符串运算符
下表实例变量 a 值为字符串 “Hello”,b 变量值为 “Python”:
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | a + b 输出结果: HelloPython |
| * | 重复输出字符串 | a*2 输出结果:HelloHello |
| [] | 通过索引获取字符串中字符 | a[1] 输出结果 e |
| [ : ] | 截取字符串中的一部分,遵循左闭右开原则,str[0:2] 是不包含第 3 个字符的。 | a[1:4] 输出结果 ell |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | ‘H’ in a 输出结果 True |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | ‘M’ not in a 输出结果 True |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母 r(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | print( r'\n' ) print( R'\n' ) |
| % | 格式字符串 | 请看下一节内容。 |
格式化字符串
Python 支持格式化字符串的输出 。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
在 Python 中,字符串格式化使用与 C 中 sprintf 函数一样的语法。
实例(Python 3.0+)
#!/usr/bin/python3 print (“我叫 %s 今年 %d 岁!” % (‘小明’, 10))
以上实例输出结果:
1 | 我叫 小明 今年 10 岁! |
格式化操作符辅助指令:
| 符号 | 功能 |
|---|---|
| * | 定义宽度或者小数点精度 |
| - | 用做左对齐 |
| + | 在正数前面显示加号( + ) |
| <sp> | 在正数前面显示空格 |
| # | 在八进制数前面显示零(‘0’),在十六进制前面显示’0x’或者’0X’(取决于用的是’x’还是’X’) |
| 0 | 显示的数字前面填充’0’而不是默认的空格 |
| % | ‘%%’输出一个单一的’%’ |
| (var) | 映射变量(字典参数) |
| m.n. | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。
f-string(Python 3.6+)
字面量格式化字符串,f-string 格式化字符串以 f 开头,后面跟着字符串,字符串中的表达式用大括号 {} 包起来,它会将变量或表达式计算后的值替换进去,实例如下:
1 | name = 'Runoob' |
在 Python 3.8 的版本中可以使用 = 符号来拼接运算表达式与结果:
1 | x = 1 |
运算符
**幂运算
//返回商的整数部分,向下取整
逻辑运算符
and
or
not
成员运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True。具体:是key是否在序列中,不是value |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 |
身份运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 **id(a) != id(b)**。如果引用的不是同一个对象则返回结果 True,否则返回 False。 |
id(a)取a的地址
is判断内存空间,==只判断值是否相等
运算符优先级
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 ‘AND’ |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
以下测试情况会==在交互模式下出现==,脚本模式 is 和 == 结果是一样的。
python中会为每个出现的对象分配内存,哪怕他们的值完全相等(注意是相等不是相同)。如执行a=2.0,b=2.0这两个语句时会先后为2.0这个Float类型对象分配内存,然后将a与b分别指向这两个对象。所以a与b指向的不是同一对象:
2
3
4
5
6
7
b=2.0
a is b
False
a==b
True
e但是为了提高内存利用效率对于一些简单的对象,如一些数值较小的int对象,python采取重用对象内存的办法,如指向a=2,b=2时,由于2作为简单的int类型且数值小,python不会两次为其分配内存,而是只分配一次,然后将a与b同时指向已分配的对象:
2
3
4
5
6
b=2
a is b
True
a==b
True上面的数值具体到小于等于256,但果赋值的不是2而是大的数值,情况就跟前面的一样了:
2
3
4
5
6
b=4444
a is b
False
a==b
Truepython 创建了一个小型整型池来存放这些可以用一个字节表示的数,这样做避免了为小点数值重复分配内存,也即重复创建对象,提高了语言运行性能。
另:如果写在同一行,就指向同一个对象
数据类型转换
| 函数 | 描述 |
|---|---|
| [int(x ,base]) | 将x转换为一个整数 |
| float(x) | 将x转换到一个浮点数 |
| [complex(real ,imag]) | 创建一个复数 |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个 (key, value)元组序列。 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
推导式
列表推导式
1 | [表达式 for 变量 in 列表] |
字典推导式
1 | { key_expr: value_expr for value in collection if condition } |
集合推导式
1 | { expression for item in Sequence if conditional } |
元组推导式
1 | (expression for item in Sequence if conditional ) |
语句
条件语句
1 | if (condition): |
字典映射代替switch
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
def zero():
return "zero"
def one():
return "one"
def two():
return "two"
def num2Str(arg):
switcher={
0:zero,
1:one,
2:two,
3:lambda:"three"
}
func=switcher.get(arg,lambda:"nothing")
return func()
if __name__ == '__main__':
print num2Str(0)
循环语句
1 | while condition: |
迭代器
字符串,元组和列表都可以创建迭代器
iter next
1 | list = [1,2,3,4] |
创建一个迭代器
把一个类作为一个迭代器使用需要在类中实现两个方法 iter() 与 next() 。
如果你已经了解的面向对象编程,就知道类都有一个构造函数,Python 的构造函数为 init(), 它会在对象初始化的时候执行。
更多内容查阅:Python3 面向对象
iter() 方法返回一个特殊的迭代器对象, 这个迭代器对象实现了 next() 方法并通过 StopIteration 异常标识迭代的完成。
next() 方法(Python 2 里是 next())会返回下一个迭代器对象。
创建一个返回数字的迭代器,初始值为 1,逐步递增 1:
1 | class MyNumbers: |
StopIteration
StopIteration 异常用于标识迭代的完成,防止出现无限循环的情况,在 next() 方法中我们可以设置在完成指定循环次数后触发 StopIteration 异常来结束迭代。
在 20 次迭代后停止执行:
1 | class MyNumbers: |
生成器
在 Python 中,使用了 yield 的函数被称为生成器(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
调用一个生成器函数,返回的是一个迭代器对象。
以下实例使用 yield 实现斐波那契数列:
1 | #!/usr/bin/python3 |
函数
函数定义
1 | def funname( str ): |
参数传递
在 python 中,类型属于对象,变量是没有类型的:
1 | a=[1,2,3] |
以上代码中,**[1,2,3]** 是 List 类型,**”Runoob”** 是 String 类型,而变量 a 是没有类型,她仅仅是一个对象的引用(一个指针),可以是指向 List 类型对象,也可以是指向 String 类型对象。
可更改(mutable)与不可更改(immutable)对象
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
- 不可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变 a 的值,相当于新生成了 a。
- 可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
python 函数的参数传递:
- 不可变类型:类似 C++ 的值传递,如整数、字符串、元组。如 fun(a),传递的只是 a 的值,没有影响 a 对象本身。如果在 fun(a) 内部修改 a 的值,则是新生成一个 a 的对象。
- 可变类型:类似 C++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后 fun 外部的 la 也会受影响
python 中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象。
参数todo!!!
导包
1 | import somemodule |
基础操作
1 | dir(math) # 查看包中内容 |
